Kompresja to proces zmniejszania objętości danych lub materiałów. Ma zastosowanie zarówno w fizyce, jak i informatyce. W fizyce polega na zmniejszeniu objętości właściwej substancji. W informatyce to redukcja rozmiaru plików. Kompresja ma wiele zalet. Oszczędza miejsce na dysku. Przyspiesza transfer danych. Ułatwia zarządzanie informacjami.
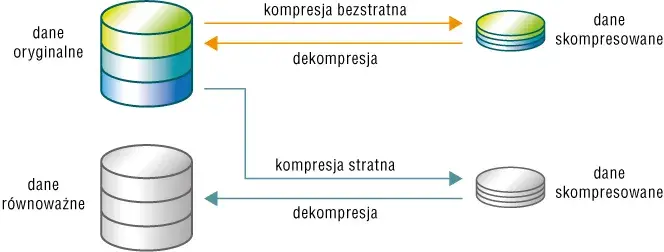
Wyróżniamy dwa główne typy kompresji danych: bezstratną i stratną. Bezstratna pozwala odtworzyć oryginalne dane bez utraty jakości. Stratna usuwa część informacji, zmniejszając rozmiar pliku kosztem jakości.
Kluczowe informacje:- Kompresja w fizyce dotyczy zmniejszenia objętości substancji
- W informatyce kompresja redukuje rozmiar plików
- Istnieją dwa typy kompresji: bezstratna i stratna
- Kompresja oszczędza miejsce i przyspiesza transfer danych
- Popularne formaty kompresji to ZIP, PNG, JPEG i MP3
Czym jest kompresja danych?
Kompresja danych to proces zmniejszania rozmiaru plików cyfrowych. Polega na usuwaniu nadmiarowych informacji lub zmianie sposobu ich zapisu. Celem jest redukcja zajmowanej przestrzeni dyskowej.
W fizyce kompresja oznacza zmniejszenie objętości substancji. W informatyce skupia się na redukcji rozmiaru danych cyfrowych. Obie dziedziny dążą do efektywniejszego wykorzystania przestrzeni, choć w różnych kontekstach.
Kompresja jest kluczowa w erze cyfrowej, umożliwiając efektywne przechowywanie i przesyłanie ogromnych ilości danych.
Kompresja w fizyce vs. kompresja w informatyce
Kompresja w fizyce dotyczy materii. Zmniejsza objętość substancji, często zwiększając jej gęstość. Przykładem jest ściskanie sprężyny lub kompresja gazu w silniku.
Kompresja danych w informatyce operuje na informacjach cyfrowych. Redukuje rozmiar plików poprzez eliminację redundancji lub stosowanie efektywniejszych metod kodowania.
- Fizyka: sprężanie gazów w silnikach
- Fizyka: kompresja materiałów w produkcji
- Informatyka: zmniejszanie rozmiaru zdjęć
- Informatyka: archiwizacja dokumentów
- Informatyka: optymalizacja transmisji danych
Rodzaje kompresji danych
Kompresja danych dzieli się na dwa główne typy: bezstratną i stratną.
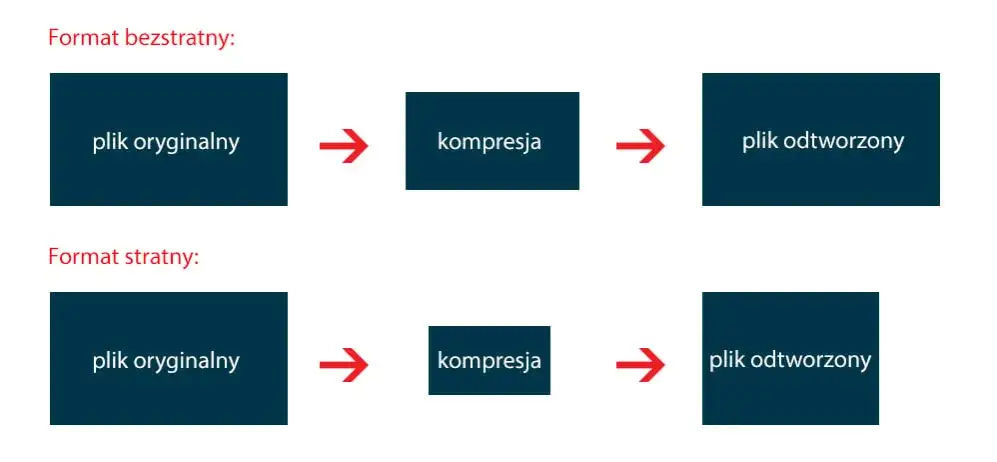
Kompresja bezstratna
Kompresja bezstratna zachowuje 100% oryginalnych danych. Wykorzystuje algorytmy, które eliminują redundancję bez utraty informacji. Po dekompresji otrzymujemy identyczną kopię oryginału.
- Zaleta: pełne zachowanie danych
- Zaleta: idealna dla dokumentów i kodów źródłowych
- Wada: mniejszy stopień kompresji
- Wada: dłuższy czas kompresji i dekompresji
Popularne formaty to ZIP, PNG i FLAC.
Kompresja stratna
Kompresja stratna usuwa część danych, które są najmniej istotne dla ludzkiego oka lub ucha. Pozwala osiągnąć znacznie większy stopień kompresji, kosztem pewnej utraty jakości.
- Zaleta: wysoki stopień kompresji
- Zaleta: mniejsze pliki, szybszy transfer
- Wada: nieodwracalna utrata części danych
- Wada: możliwe pogorszenie jakości przy wielokrotnej kompresji
Najpopularniejsze formaty to JPEG dla obrazów i MP3 dla dźwięku.
Czytaj więcej: Notatka o baroku - wszystko, co musisz wiedzieć o epoce baroku
Jak działa kompresja danych?
Kompresja danych wykorzystuje różne techniki redukcji rozmiaru plików. Najczęściej stosuje się eliminację powtórzeń, kodowanie entropijne lub transformacje matematyczne. Algorytmy analizują dane, szukając wzorców i redundancji. Następnie zapisują informacje w bardziej zwartej formie.
Popularne algorytmy kompresji
Huffmana: Przypisuje krótsze kody częściej występującym symbolom. Stosowany w kompresji bezstratnej, np. w formacie ZIP.
LZW (Lempel-Ziv-Welch): Tworzy słownik powtarzających się ciągów danych. Wykorzystywany w GIF i niektórych formatach bezstratnych.
JPEG: Dzieli obraz na bloki, stosuje transformatę kosinusową i kwantyzację. Powszechnie używany do kompresji zdjęć cyfrowych.
MPEG: Wykorzystuje podobieństwa między klatkami wideo. Kluczowy w kompresji filmów i transmisji strumieniowej.
| Nazwa | Typ kompresji | Efektywność | Typowe zastosowania |
| Huffmana | Bezstratna | Średnia | Archiwa, tekst |
| LZW | Bezstratna | Wysoka | GIF, TIFF |
| JPEG | Stratna | Bardzo wysoka | Fotografie |
| MPEG | Stratna | Bardzo wysoka | Wideo, streaming |
Zalety stosowania kompresji danych
- Oszczędność miejsca: Zmniejsza ilość potrzebnej przestrzeni dyskowej, co jest kluczowe przy ograniczonej pojemności.
- Szybszy transfer: Mniejsze pliki szybciej się przesyłają, co jest istotne przy wolnych łączach.
- Niższe koszty: Mniej danych to niższe koszty przechowywania i transmisji, szczególnie w chmurze.
- Efektywniejsze backupy: Skompresowane kopie zapasowe zajmują mniej miejsca i szybciej się tworzą.
- Optymalizacja baz danych: Kompresja przyspiesza operacje na dużych zbiorach danych.
- Lepsza wydajność aplikacji: Mniejsze pliki to szybsze ładowanie i przetwarzanie danych.
Zastosowania kompresji w różnych dziedzinach
Multimedia: Kompresja umożliwia przechowywanie tysięcy zdjęć i filmów na smartfonach. Pozwala na strumieniowanie wideo w wysokiej jakości przy ograniczonej przepustowości.
Telekomunikacja: Operatorzy wykorzystują kompresję danych do optymalizacji przepustowości sieci. Umożliwia to obsługę większej liczby połączeń i szybszą transmisję danych.
Medycyna: Obrazy diagnostyczne, takie jak MRI czy CT, są kompresowane dla łatwiejszego przechowywania i szybszego przesyłania między specjalistami. Stosuje się tu głównie kompresję bezstratną.
Astronomia: Ogromne ilości danych z teleskopów kosmicznych są kompresowane przed wysłaniem na Ziemię. Pozwala to na efektywne wykorzystanie ograniczonego pasma transmisji.
E-commerce: Sklepy internetowe stosują kompresję obrazów i danych produktowych. Przyspiesza to ładowanie stron i poprawia doświadczenia użytkowników.
- Rodzaj danych: Tekst, obrazy czy dźwięk wymagają różnych metod.
- Wymagana jakość: Czy możesz pozwolić sobie na utratę części danych?
- Szybkość: Czy ważniejszy jest czas kompresji czy stopień zmniejszenia rozmiaru?
- Zgodność: Sprawdź, jakie formaty są obsługiwane przez docelowe systemy.
Wyzwania i ograniczenia kompresji danych
Kompromis jakość-rozmiar: Większa kompresja często oznacza niższą jakość, szczególnie w przypadku metod stratnych. Znalezienie odpowiedniego balansu może być trudne.
Złożoność obliczeniowa: Zaawansowane algorytmy kompresji wymagają znacznej mocy obliczeniowej. Może to prowadzić do dłuższych czasów kodowania i dekodowania, szczególnie na słabszych urządzeniach.
Podatność na błędy: Skompresowane dane są bardziej wrażliwe na uszkodzenia. Nawet drobne błędy mogą uniemożliwić odtworzenie całego pliku, zwłaszcza w przypadku kompresji bezstratnej.
Ograniczenia prawne: Niektóre algorytmy kompresji są objęte patentami. Może to ograniczać ich wykorzystanie w pewnych zastosowaniach komercyjnych lub open-source.
Przyszłość kompresji danych
Uczenie maszynowe w kompresji: Algorytmy AI uczą się optymalnych metod kompresji dla różnych typów danych. Pozwala to na automatyczną adaptację do specyfiki konkretnych plików, osiągając lepsze wyniki niż tradycyjne metody.
Kompresja kwantowa: Badania nad wykorzystaniem własności mechaniki kwantowej do kompresji danych obiecują przełom. Potencjalnie umożliwi to znacznie wyższe stopnie kompresji niż obecne metody klasyczne.
Dedykowane układy sprzętowe: Rozwój specjalizowanych chipów do kompresji przyspieszy proces i zmniejszy zużycie energii. Umożliwi to efektywniejszą kompresję w czasie rzeczywistym, nawet na urządzeniach mobilnych.
Kompresja danych: klucz do efektywnego zarządzania informacjami w erze cyfrowej
Kompresja danych to fundamentalna technika w świecie cyfrowym, umożliwiająca efektywne przechowywanie i przesyłanie ogromnych ilości informacji. Dzięki metodom bezstratnym i stratnym, możemy znacząco redukować rozmiary plików, zachowując jednocześnie ich funkcjonalność i użyteczność.
Od prostych algorytmów Huffmana po zaawansowane metody wykorzystujące sztuczną inteligencję, kompresja nieustannie ewoluuje. Jej zastosowania obejmują szerokie spektrum dziedzin - od multimedów i telekomunikacji po medycynę i astronomię. Mimo wyzwań, takich jak kompromis między jakością a rozmiarem czy złożoność obliczeniowa, kompresja danych pozostaje kluczowym narzędziem w optymalizacji wykorzystania zasobów cyfrowych.
Przyszłość kompresji rysuje się fascynująco, z perspektywami wykorzystania uczenia maszynowego, mechaniki kwantowej i dedykowanych układów sprzętowych. Te innowacje obiecują jeszcze efektywniejsze metody redukcji danych, co będzie miało ogromne znaczenie w świecie coraz bardziej zależnym od szybkiego i wydajnego przetwarzania informacji.